
デジタルツイン/AI型第3世代BI Geminiotには、AI・機械学習のアルゴリズムを用いた分類問題の推定や数値の予測、クラスタリングを手軽に始められる機能が備わっています。
本製品を利用し始めた方の多くは、まずは身近で収集できるデータを使ってインサイトAIの機能をお試しいただくことが多いのではないでしょうか。その際、どのようなデータならうまくモデルが作れるのか、機械学習を行うにあたり注意しておくポイントは無いかなど気になる点があるかもしれません。
実際にGeminiotのユーザー様からAI・機械学習を行う際のデータの取り扱い方について様々な質問を頂くことがあります。
・どのようなデータの粒度や項目の持たせ方をすれば良いか?
・意図した結果を出すためにはどのような情報を集めれば良いのか?
など様々です。
今回はそれらの中でも分類問題を扱う場合に気を付けておくべき不均衡データの取り扱いについてご紹介致します。不均衡データは身近でも頻繁に見かけるデータなので、Geminiotで分析をされる際の一助となれば幸いです。
不均衡データとは
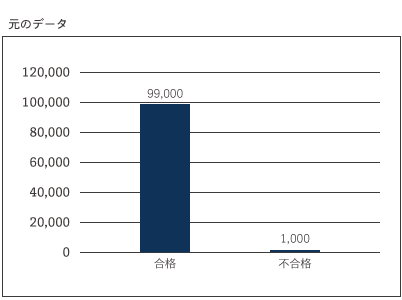
不均衡データとは、機械学習で分類の推定(教師あり)を行う場合に、目的変数(分析したい対象)の各クラスの比率が大きく異なっているデータを指します。本記事では、生産ラインで量産される製品Aを10万個検品した結果を合格と不合格に振り分けるような例を考えてみます。

この製品Aの生産ラインは自動化されていて品質が安定しているため不良はめったに出ません。殆どの製品は合格となるため各クラスの比率が大きく異なった状態になっています。この状態を不均衡な状態と言い、件数が多い方のクラスを「メジャークラス」や「多数クラス」、少ない方を「マイナークラス」や「少数クラス」などと呼びます。
不均衡なデータは身近に数多く発生しうるものである一方、マイナークラスの事象が発生した場合のインパクトの大きさから対策が必要になることがあります。上記の例では1%の不良が業績に影響を及ぼしてしまうため、さらに品質を安定させるために不良の原因を分析・対策したり、予測モデルを作って検品前に不良品の発生有無を予測したいといったニーズがあるかもしれません。
上記の例以外にも、精密機器の故障や医療における特定の疾患の重症化など、発生時のインパクトが大きいものに対しては発生原因を分析して未然に防ぐための対策を求められることがあります。
不均衡データの問題点
不均衡データを分析する際にどのような問題点があるか考えてみましょう。まず、分類問題で扱われる一般的な教師あり機械学習のアルゴリズムがどのような振る舞いをするのかを整理します。内容を分かりやすくするために抽象化していますが、概ね以下のようなイメージと捉えてください。
(1) 結果に影響を与える指標と実際の結果のセットから両者の関係を表すことのできる計算式を作り出します。
(2) 作り出した計算式を使って推測した結果と、実際の結果とを比較して誤差率が小さくなくなるように計算式の内容を調整します。
(3) (1)~(3)を繰り返し、誤差率が最も少なくなる計算式を決定します。
つまり、学習モデルは誤差率の最小化を目的として設計されていると言えます。このことが不均衡データを機械学習を行う際の問題点につながります。
不均衡な状態のデータで構築されたモデルは、結果をメジャークラスの方に予測しがちです。クラス間の偏りが大きく、データの殆どがメジャークラスなのであれば、未知のデータもメジャークラスに分類してしまえば高確率で正解になるからです。先ほどの製品Aを10万個検品した例で考えてみます。
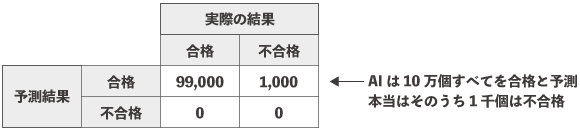
極端な例ですが、AIは10万件すべての製品を合格と予測し、不合格となるケースを一つも正解できていません。にもかかわらず、このモデルで予測した結果の正答率は99%と非常に高くなってしまいます。誤差率をなるべく少なくするという事が目的であれば上記のような予測をするモデルも良いモデルという事になります。
しかし、実際にはマイナークラスの特徴をうまく学習できていないため、不合格になるような状態であっても検知できない状態です。これが不均衡データで機械学習を行う際の問題点です。
対処の方法は一般的なものでは大きく分けて2種類あります。
・データそのものを加工して不均衡を取り除く方法
・適切なモデル精度の評価指標を設定する方法
2つ目の適切なモデル制度の評価指標を設定する方法については、特定のクラスを重視する設定や全クラスを平等に扱う設定などがありますが、詳しい内容は別の記事でさせて頂くとして、本記事内では実践しやすい「データそのものを加工して不均衡を取り除く方法」について解説いたします。
データそのものを加工して不均衡を取り除く方法
まず基本的な考え方ですが、データを”増やす”または、データを”減らす”ことで各クラスの比率を揃え、不均衡を解消します。具体的な方法としては以下の2種類が一般的です。
UnderSampling(またはDownSampling)
マイナークラスのデータ量に合わせてメジャークラスのデータを削除する方法です。元々のデータ量が多い場合に有効ですが、逆に元々のデータ量が少ないものに採用してしまうと分析に必要なデータ量を確保できなくなってしまうため注意が必要です。メジャークラスのどのデータを削除するかについては、様々な方法がありますが、ランダムに選び取る方法が一般的で実装が容易です。
OverSampling (またはUpSampling)
メジャークラスのデータ量に合わせてマイナークラスのデータを嵩増しする方法です。元々のデータ量が少ない場合に有効ですが、逆に元々のデータ量が多いものに採用してしまうと計算量が膨大になり、マシンリソースを占有してしまう可能性があるため注意が必要です。マイナークラスのどのデータを嵩増しするかについては、様々な方法がありますが、ランダムに選び取る方法が一般的で実装が容易です。
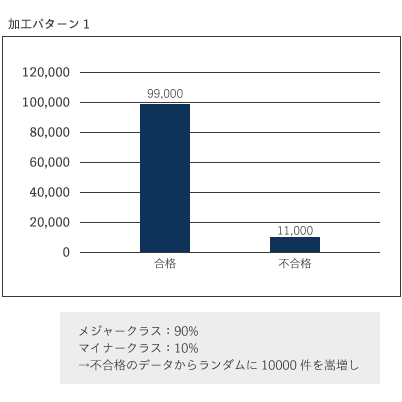
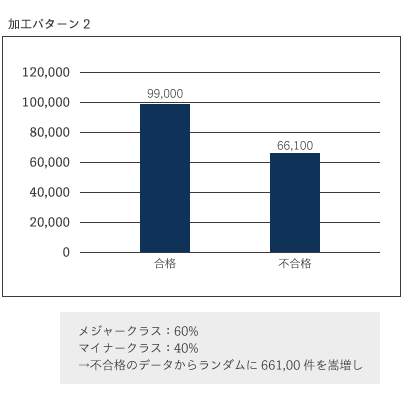
どちらの手法においても、どの程度の比率になるように削除or嵩増しするのかについては明確な答えはありません。より精度の良いモデルになるようにいくつかのパターンを試しながら見極めていく必要があります。
Geminiotでの実装例
ここでは一例としてGeminiotのデータフローでUnderSamplingを行う方法をご紹介します。実際にお試しいただく際の参考にしてください。実装例で扱うデータは本記事で例示した製品A10万個の検品結果データです。
※データフローの詳細な使い方はヘルプメニューおよび別記事をご参照ください。
csvファイルをGeminiotに取り込む
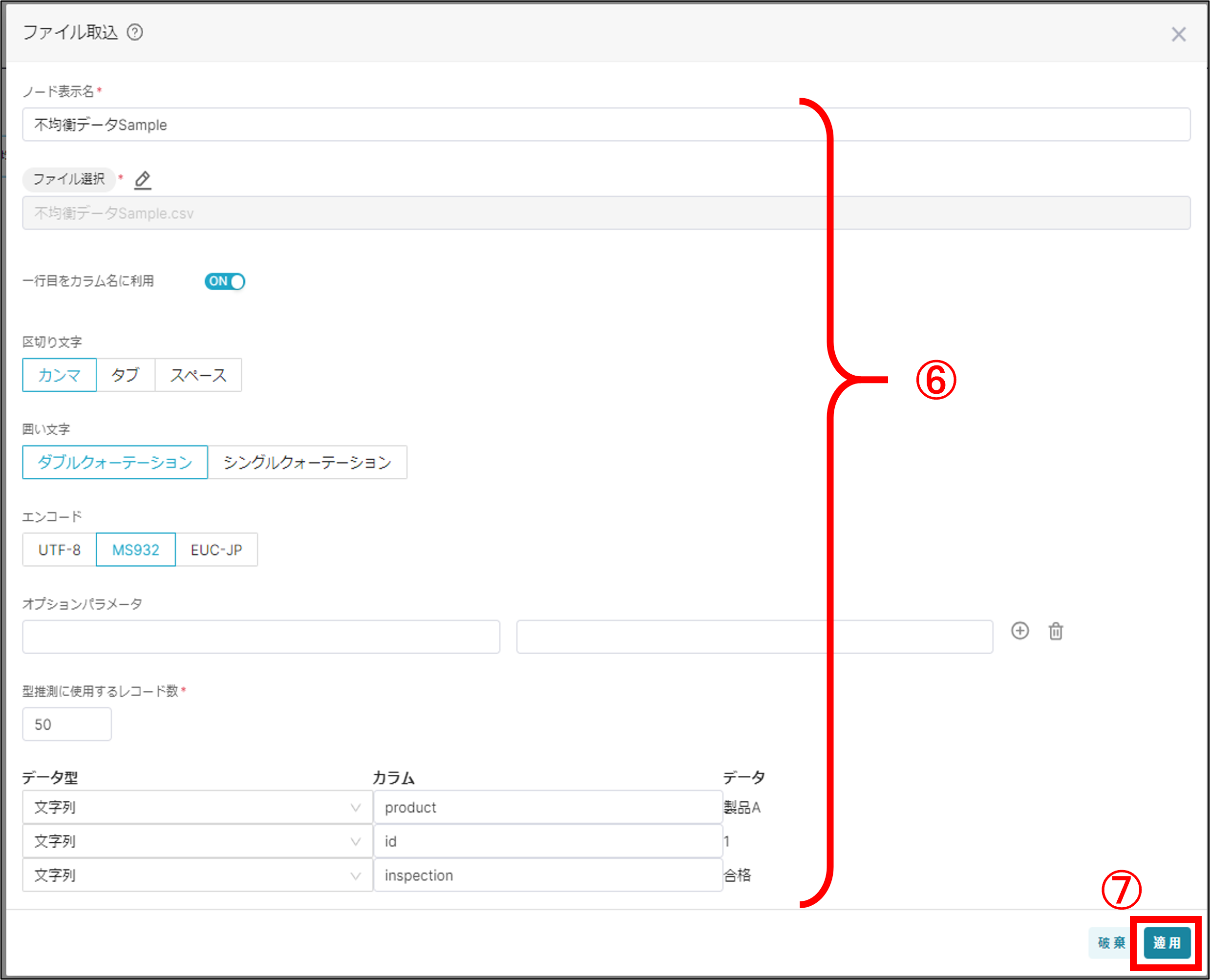
(1)「Data」タブ内の「Dataflow」を開き、「+データフロー追加」ボタンをクリック
(2)画面左「INPUT」タブ内の「ファイル取込」ノードをドラッグ&ドロップ
(3)「ファイル取込」ノードをダブルクリックし設定画面を開く
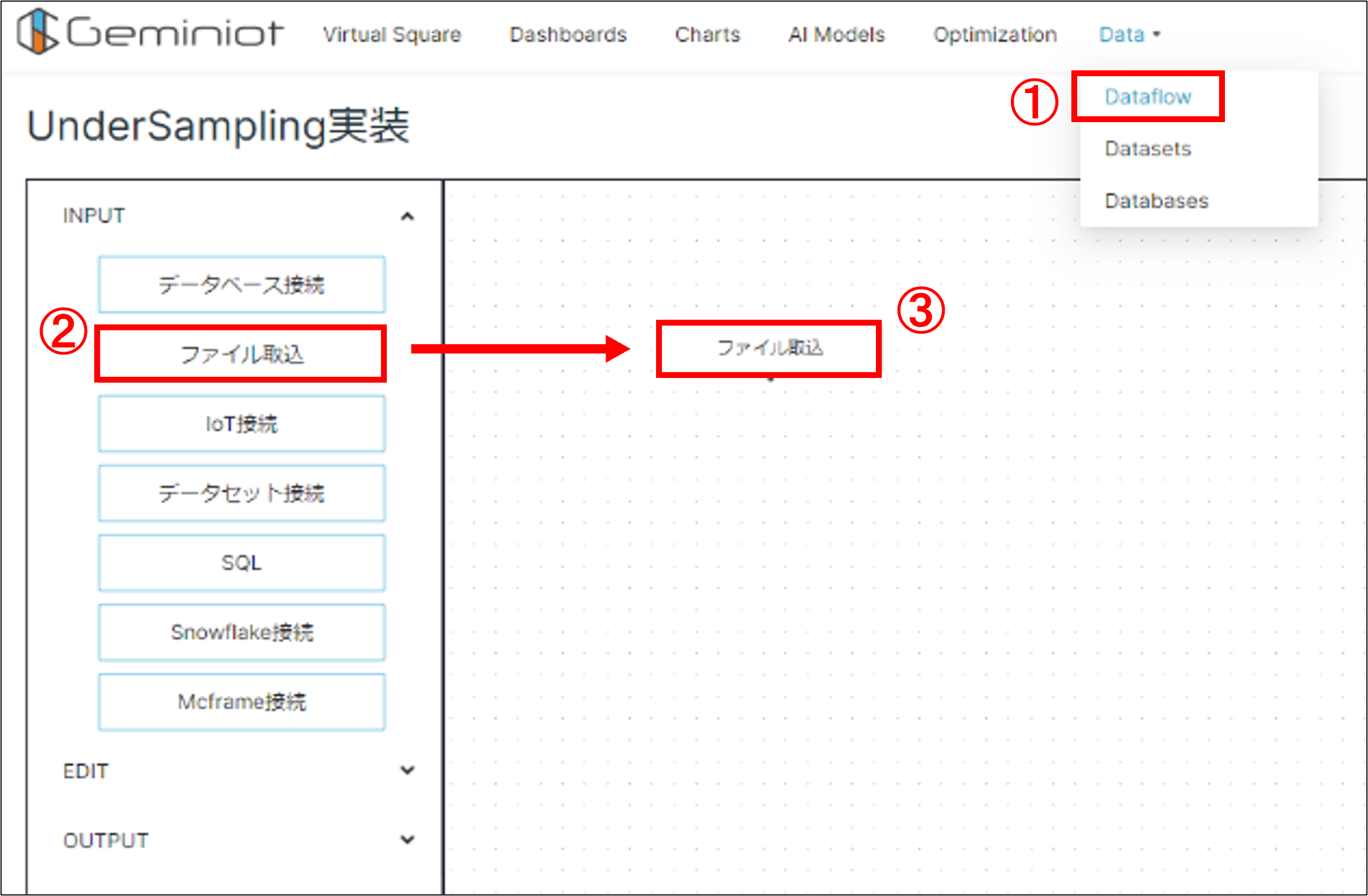
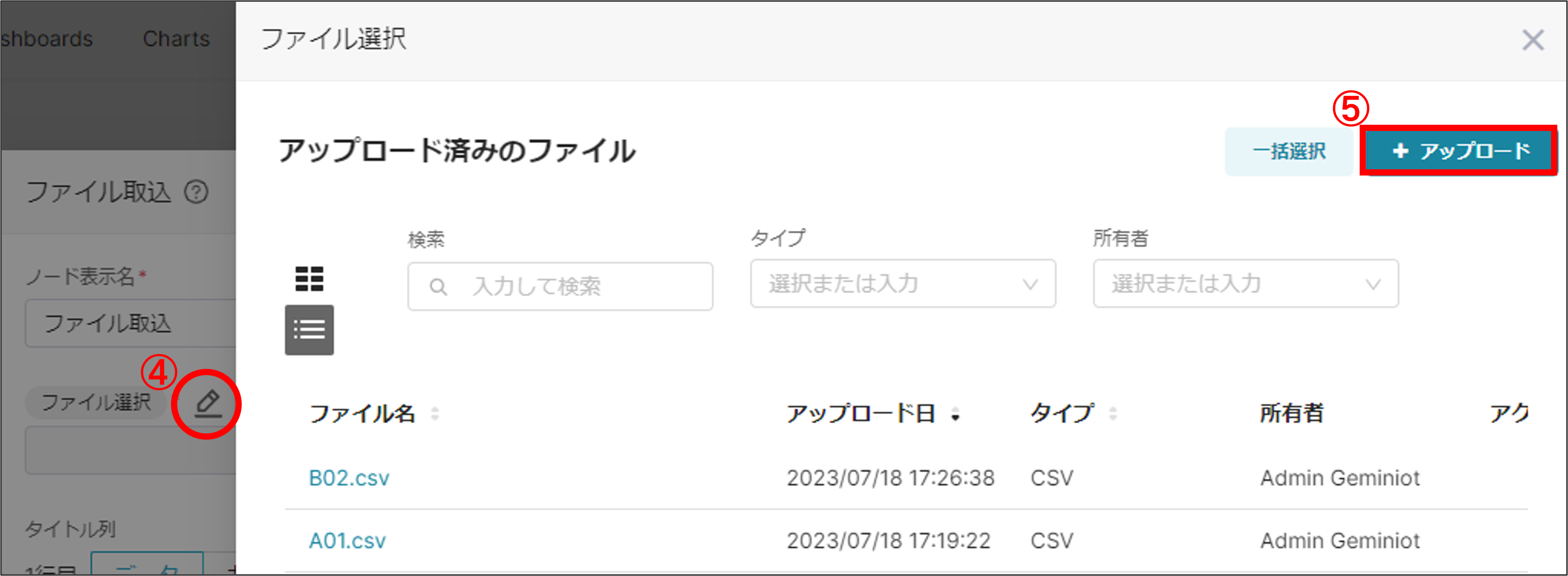
(4)「ファイル選択」欄の右にある鉛筆マークをクリック
(5)「+アップロード」ボタンをクリックし、アップロードしたいcsvファイルを選択
(6)設定画面に戻り、ノード名やタイトル列情報、データ型などを設定
(7)設定が完了したら「適用」ボタンで保存
SQL編集ノードを使ってUnderSamplingを実施
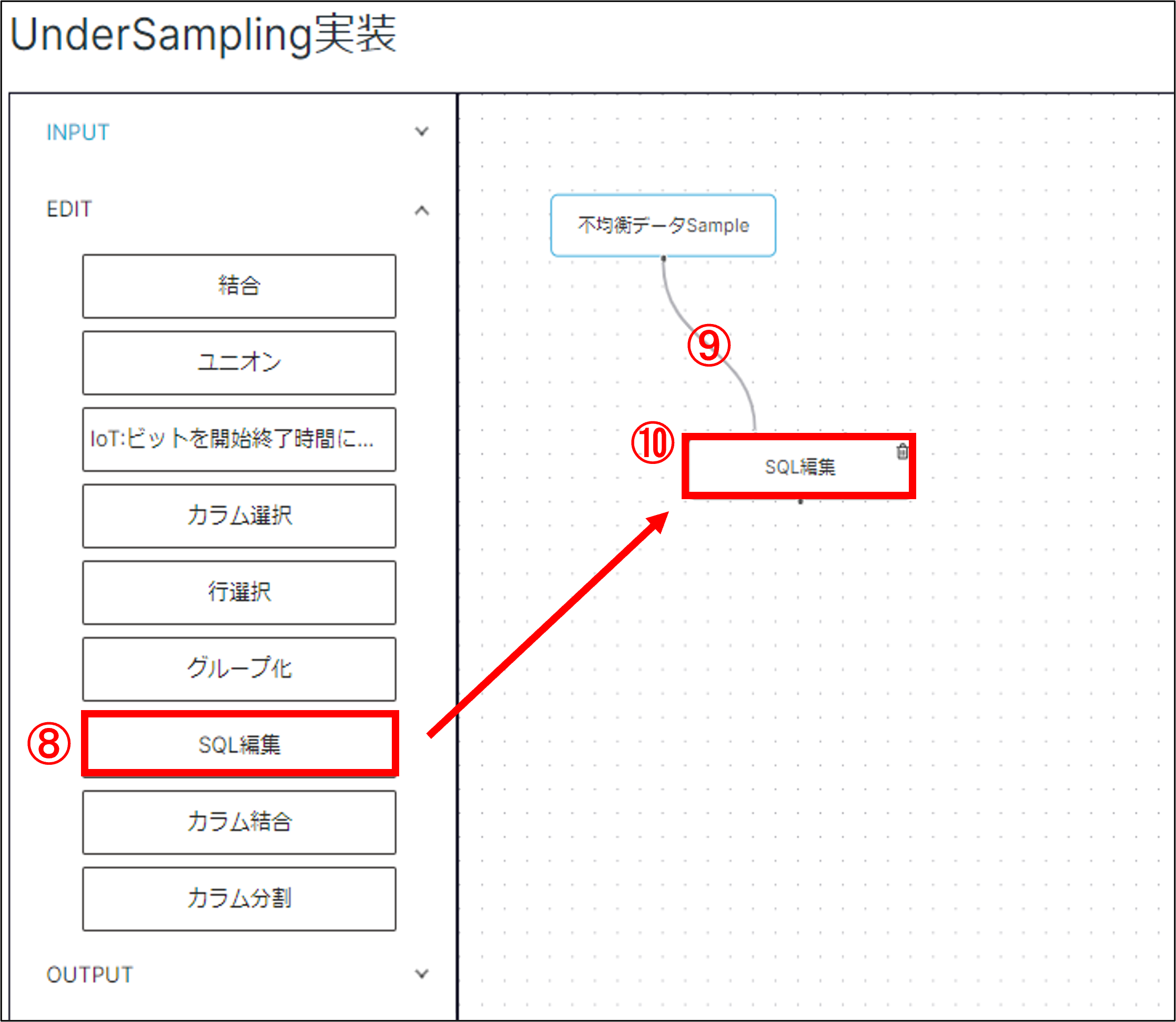
(8)「EDIT」タブ内「SQL編集」ノードをドラッグ&ドロップ
(9)「ファイル取込」ノードと「SQL編集ノード」を線でつなぐ
(10)「SQL編集」ノードをダブルクリックして設定画面を開く
(11)テーブル名に任意の名前を付ける
(12)クエリを書く
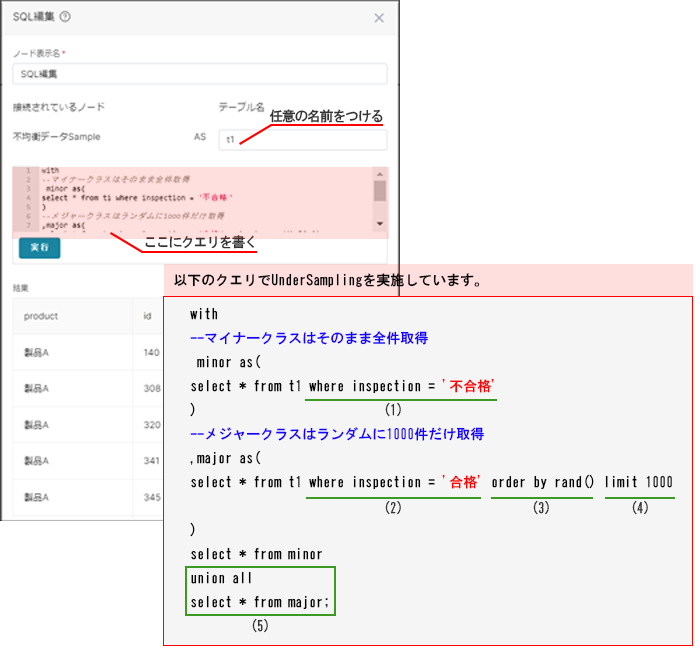
(1) 10万件の検品結果のなかで不合格だったもののみを指定する
(2) 10万件の検品結果のなかで合格だったもののみを指定する
(3) データをランダムな順番に並べ替える
(4) データを上から1000件だけ取得する
(5) 不合格のデータとランダムに1000件に絞った合格のデータを縦に繋げる
データセットとして出力
(13)「OUTPUT」タブ内の「データセット出力」をドラッグ&ドロップ
(14)「SQL編集」ノードと「データセット出力」ノードをつなぐ
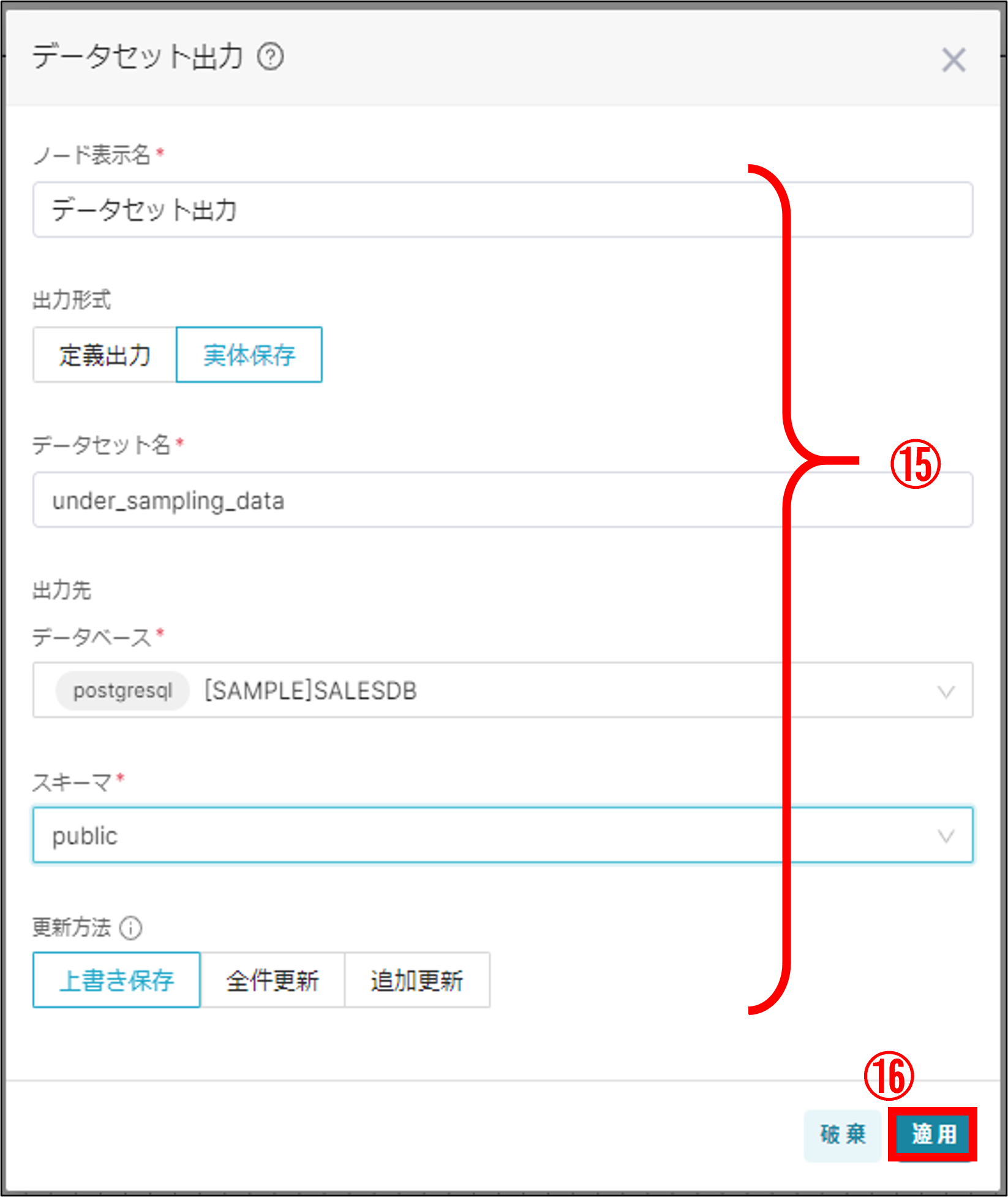
(15)「データセット出力」をダブルクリックして出力情報を設定
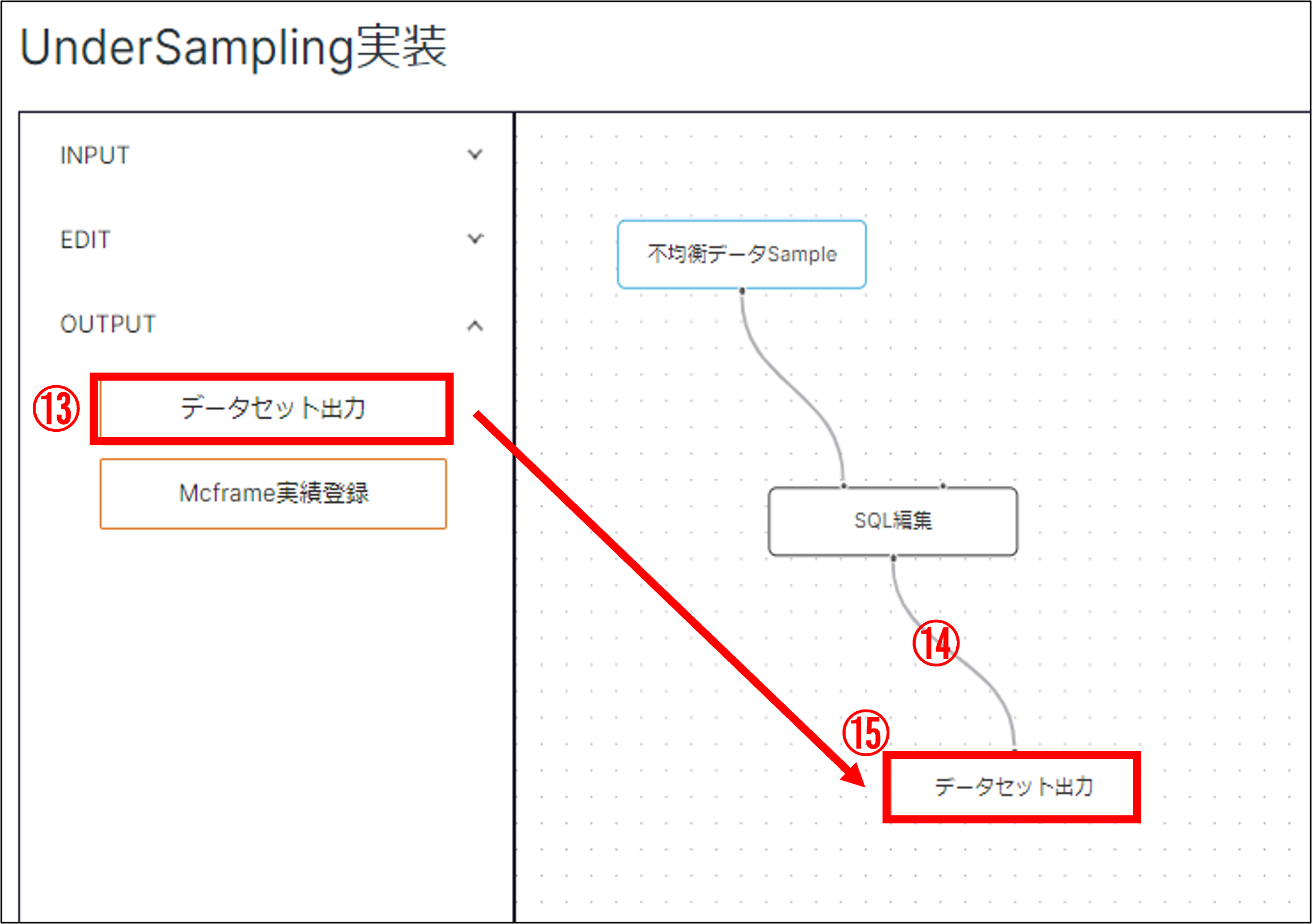
(16)設定が完了したら「適用」ボタンで保存
出力したデータを見ると、両クラスとも1,000件ずつになっていることが確認できました。

初期費用0円!ユーザー登録ですぐにご利用いただけます。